使用 MacBook Pro M1 16G 运行 Llama 2 7B (Apple Silicon 通用方法)
2023-11-04 21:09:45 Cyberbolt
这篇文章用于记录我在 MacBook Pro M1 16G 中配置 Llama 2 7B 环境的全流程。这一方法适用于所有 Apple Silicon 系列,为未来运行更大模型的设备提供参考。
PS:得益于 Mac 的统一内存,我们可以将内存作为显存使用,使大模型的本地部署成为了可能。如今 Apple Silicon 拥有完善的 LLM 生态,llama.cpp 项目让我们能在 Mac GPU 上运行 Llama 2,这也成为目前性价比最高的大模型运行方案。期待在 M3 时代,Apple Silicon 在 AI 领域取得进一步发展。
测试环境:
macOS 14.0
Miniforge 创建的 Python 3.10.0 (也可以使用 Miniconda)
Chinese-Alpaca-2-7B
以下是详细步骤:
进入终端,使用 conda 创建全新的虚拟环境
conda create -n llama python=3.10
激活虚拟环境
conda activate llama
将 llama.cpp 拉到本地
git clone https://github.com/ggerganov/llama.cpp.git
切换到 llama.cpp 目录
cd llama.cpp
安装依赖
pip install -r requirements.txt
编译 llama.cpp,并开启 GPU 推理
LLAMA_METAL=1 make
下载 Chinese-LLaMA-2-7B,地址: https://github.com/ymcui/Chinese-LLaMA-Alpaca-2#完整模型下载
将下载好的模型目录拷贝至当前目录 (llama.cpp) 的 models 中。(得到模型目录位置为 llama.cpp/models/chinese-alpaca-2-7b-hf)
生成量化版本模型
python convert.py models/chinese-alpaca-2-7b-hf/
./quantize ./models/chinese-alpaca-2-7b-hf/ggml-model-f16.gguf ./models/chinese-alpaca-2-7b-hf/ggml-model-q4_0.gguf q4_0
在当前目录中创建 shell 脚本 chat.sh
#!/bin/bash
# temporary script to chat with Chinese Alpaca-2 model
# usage: ./chat.sh alpaca2-ggml-model-path your-first-instruction
SYSTEM='You are a helpful assistant. 你是一个乐于助人的助手。'
FIRST_INSTRUCTION=$2
./main -m $1 \
--color -i -c 4096 -t 8 --temp 0.5 --top_k 40 --top_p 0.9 --repeat_penalty 1.1 \
--in-prefix-bos --in-prefix ' [INST] ' --in-suffix ' [/INST]' -p \
"[INST] <>
$SYSTEM
<>
$FIRST_INSTRUCTION [/INST]"
设置可执行权限
chmod +x chat.sh
然后使用以下命令运行即可
./chat.sh models/chinese-alpaca-2-7b-hf/ggml-model-q4_0.gguf '作为一个 AI 助手,你可以帮助人类做哪些事情?'
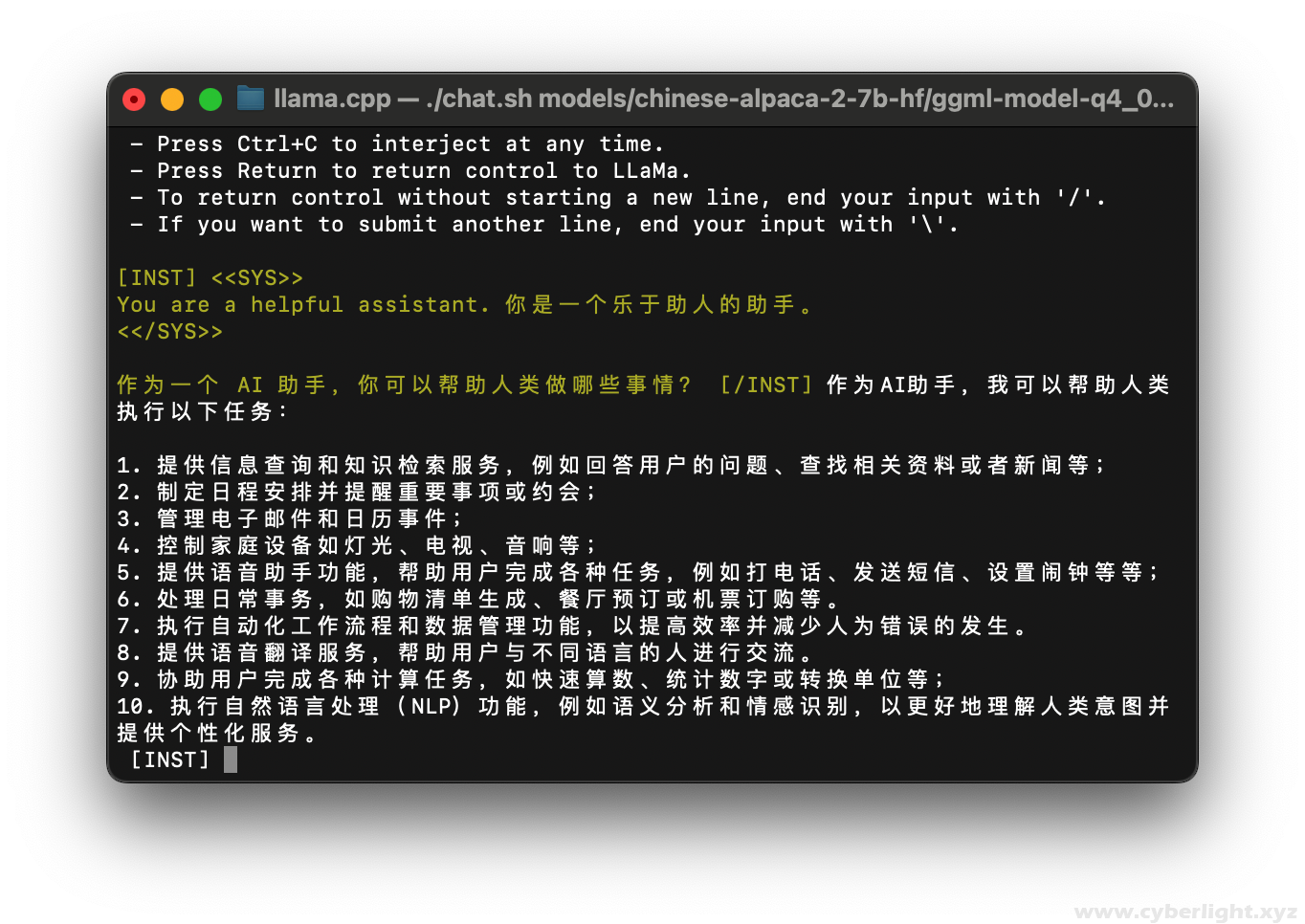
成功运行~
(未来考虑使用 M3 Max 128G 或更高规格的 Mac 试试)
2023-11-25 11:02:31
请问chat ui怎么做呢

2023-12-01 20:38:08
回复 wow: 找开源项目,或者自己开发
2023-12-03 17:49:34
回复 Cyberbolt: 好的 再请教下 mac intel芯片的可以跑么

2024-11-15 09:09:22
回复 wow: Muchas gracias. ?Como puedo iniciar sesion?
2024-11-15 09:09:25
回复 Cyberbolt: redirect-de1068a74f13a148437d7afe04629ee0@webmark.eting.org
2023-12-15 20:27:13
请问部署好后可以微调吗,用自己的数据集在训练一次
2024-11-15 09:09:31
回复 四糸乃下仆: Muchas gracias. ?Como puedo iniciar sesion?
2024-04-15 09:49:11
第一步就提示:-bash: conda: command not found,是需要先安装python什么的环境吗?
2024-04-26 18:07:22
回复 开车油耗变大了: 本文不是 Python 的基础教程,请自行安装 conda 等环境
2024-11-15 09:09:34
回复 开车油耗变大了: Muchas gracias. ?Como puedo iniciar sesion?
2024-11-15 09:09:18
Muchas gracias. ?Como puedo iniciar sesion?